
-
добавить в избранное


Поиски и происки
10 июля 2018
«"Яндекс" раскрывает тайны пользователей», – такими новостными заголовками запестрели многие СМИ.
Вечером 4 июля 2018 г. в поисковой выдаче «Яндекса» появилась конфиденциальная информация из документов, размещенных в облачных сервисах Google Docs и Google Drive.
Среди обнаруженного были замечены, к примеру, логины и пароли от учетных записей различных веб-сервисов, данные банковских карт, отчеты о финансовых показателях и планы PR-мероприятий коммерческих организаций и другие виды чувствительной информации. Многие из попавших в открытый доступ документов оказались доступными для редактирования, поэтому подверглись вандализму. В отдельных случаях пользователи, получившие доступ к чужим документам, напротив постарались уведомить их владельцев о случившемся.
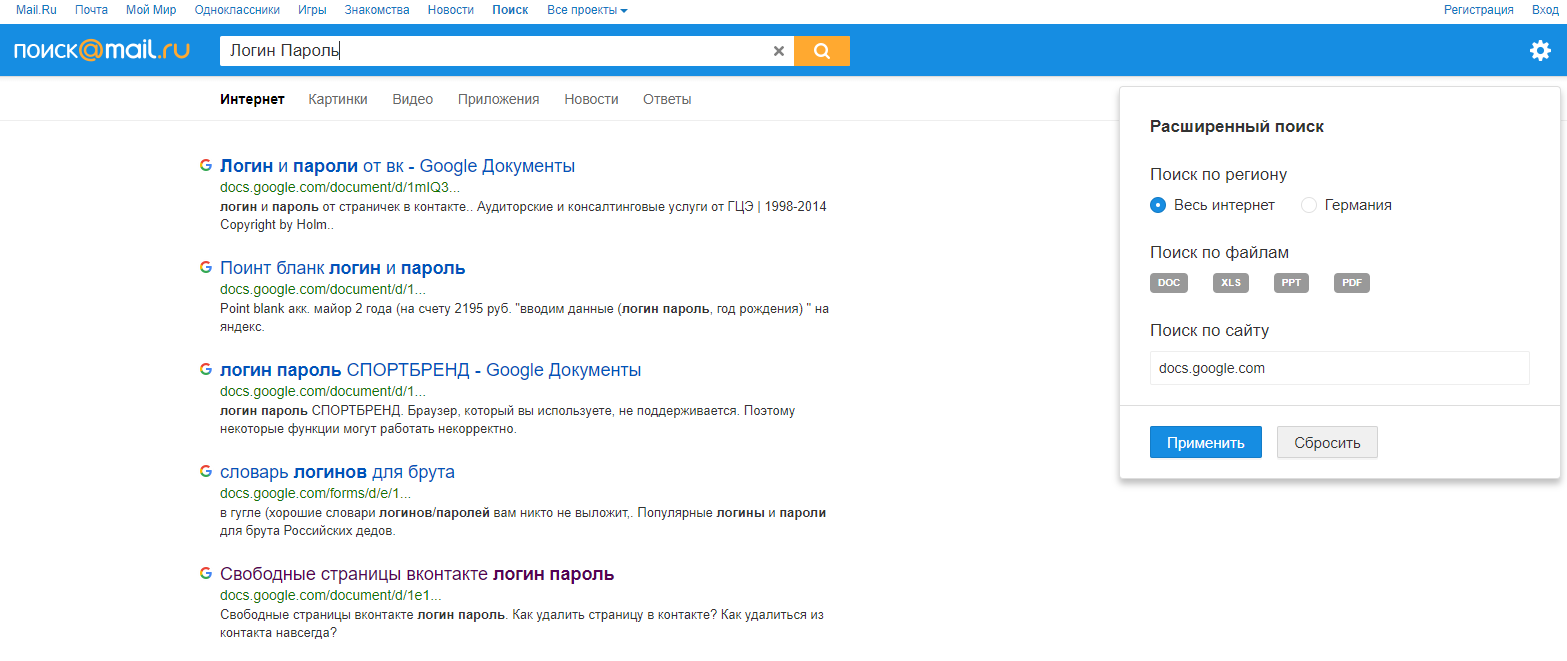
Для того, чтобы найти приватную информацию такого рода, было необходимо перейти на страницу расширенного поиска «Яндекса», где помимо ключевых слов указать также и адрес сайта, на котором осуществляется поиск. В данном случае это docs.google.com или drive.google.com.
http://safe.cnews.ru/news/top/2018-07-05_yandeks_vydal...
Только что стало известно, что Яндекс начал индексировать Google Документы, в числе которых есть и документы с паролями, личными данными и т. д.

Что произошло? «Яндекс» пошел войной на Google? Что грозит американской корпорации в связи с масштабной утечкой? Эти и многие вопросы взволновали и журналистов, и пользователей – никому не хочется, чтобы его данные оказались в свободном доступе. Попробуем разобраться.
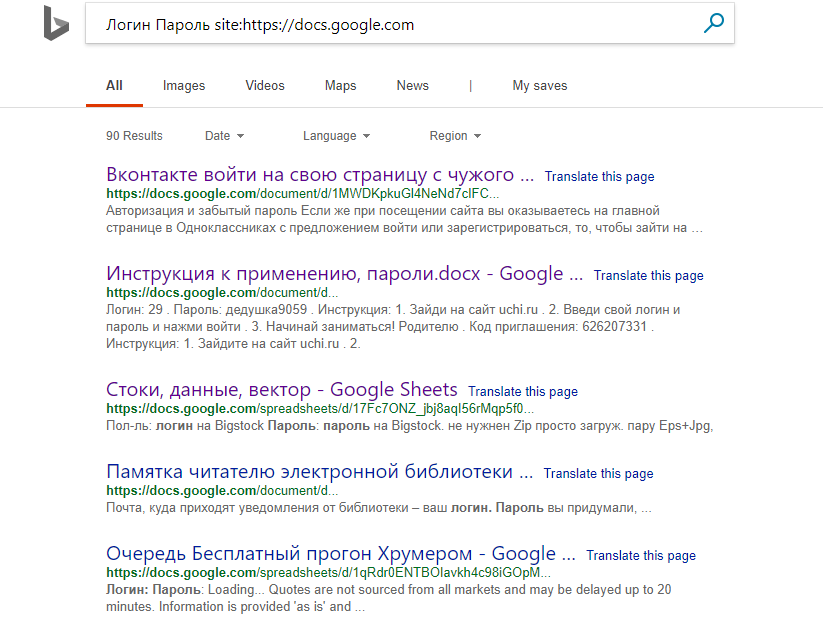
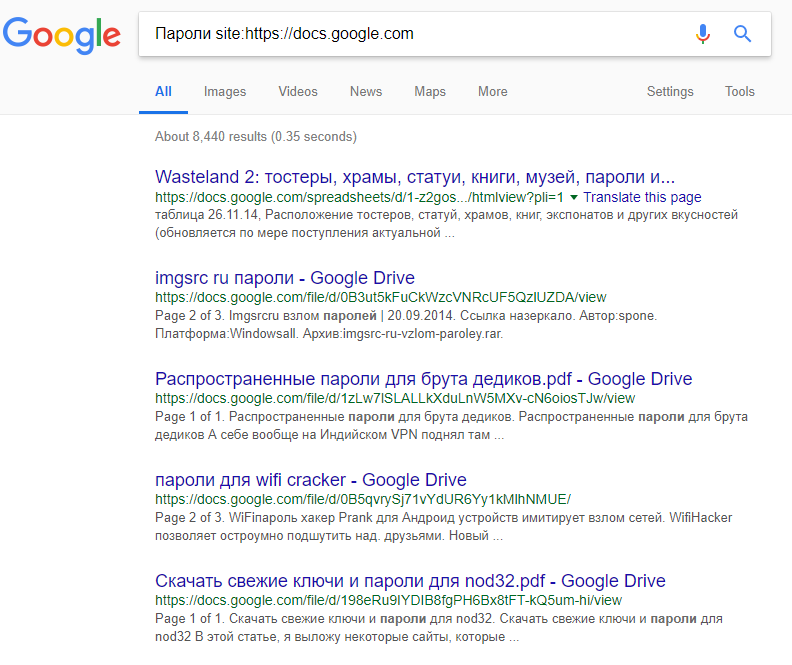
Во-первых, «Яндекс» тут ни при чем: упомянутые данные можно было найти в поисковиках Mail.ru, Bing и даже в самом Google.
Кто же виноват? А виноват маленький файл, на котором держится вся секретность данных в Интернете, – robots.txt.
Поисковые роботы перебирают доступные в Сети ресурсы, индексируют их и, используя «шаманские» алгоритмы, выдают результат по запросу пользователя. Но индексируются далеко не все ресурсы. Более того — ресурс может указать поисковому роботу сделать ли тот или иной документ доступным всем. Дело в том, что поисковые роботы, обнаружив некий сайт, не сразу приступают к индексации информации. Сначала они ищут файл robots.txt — текстовый файл в корневой директории сайта, который содержит инструкции для поисковых роботов. Эти инструкции могут запрещать индексацию некоторых разделов или страниц сайта, указывать на правильное «зеркалирование» домена, рекомендовать поисковому роботу соблюдать определенный временной интервал между скачиванием документов с сервера и т. д.
Например, запись в файле Disallow: /about запретит доступ к разделу http://__имя сайта__/about/ и к файлу http:// __имя сайта__/about.php.

По сути поисковые роботы не очень умны. Проще говоря, эти программы в ходе работы заходят на некую страницу, проверяют наличие в ее коде файла robots.txt и смотрят, не прописан ли в этом файле запрет индексировать эту страницу. Если запрета нет, индексация происходит.
У нас, например, есть продукт с централизованным управлением – Dr.Web Enterprise Security Suite. Иногда к нему требуется доступ извне сети, и администраторы делают веб-сервер Центра управления доступным из Интернета. И поисковые роботы замечательно индексируют страницы веб-сервера, хотя там ничего интересного нет и быть не может. В итоге в 11-й версии Центра управления мы тоже добавили защиту от поисковых роботов.
Как роботы проникают внутрь ресурсов? Люди заходят на страницы сайта, вводя логины и пароли. Поисковые роботы переходят по ссылкам с одной страницы на другую. Раз ссылка есть, а прямого запрета в robots.txt нет, – заходим и индексируем. И злого умысла здесь нет, так устроен Интернет. Поисковый робот переходит по ссылкам и просто не замечает, что он проник на некий сайт через уязвимость.
Вот как связаны между собой ссылками различные интернет-ресурсы:

https://kak-eto-sdelano.ru/kak-slomat-internet
Как посмотреть содержимое robots.tst какого-либо ресурса? Набираем в браузере интересующее имя сайта, косую черту и robots.txt. Скажем, https://docs.google.com/robots.txt:
...
Allow: /Doc
Allow: /View
Allow: /ViewDoc
Allow: /present
Allow: /Present
Allow: /TeamPresent
Allow: /EmbedSlideshow
Allow: /presentation
Allow: /templates
Allow: /previewtemplate
Allow: /fileview
...
Allow: /document
...
Allow: /macros
..
Заходи и смотри, что хочешь!
Вывод: произошедшее – скорее всего, ошибка программистов Google, почему-то не закрывших с помощью robots.txt доступ к страницам. Возможно также наличие уязвимости на сайте, через которую туда мог зайти кто угодно. А «Яндекс» вручную запретил своим роботам обходить некие ресурсы.
Спустя несколько часов после происшествия ссылки на Google Docs бесследно исчезли из выдачи «Яндекса», хотя поиск по Google Drive по-прежнему работал к утру 5 июля 2018 г.
О грустном. Если вы не находите в поисковике своих данных, это не значит, что найти их нельзя вручную. Представьте: на дверь дома наклеивают стикер с надписью «Закрыто». Воспитанные люди проходят мимо, а невоспитанные... Никто не мешает злоумышленникам создать свой поисковик, игнорирующий все эти детские ограничения, и – держитесь, данные!
Выкладывая в Интернет свои данные, пользователь должен понимать, что прикрыты они зачастую «фиговым листочком» – заверениями сервиса о том, что он «предпринимает все усилия»…
И в заключение. Любой поисковик не только индексирует страницы, но и может показывать данные из кэша: информация сохраняется для отображения на случай недоступности страницы (если ее не удалили вручную). Сейчас все поисковики закэшировали данные пользователей Google (и кэшируют многие другие ресурсы).
#Google #персональные_данные #Интернет #сайт #безопасностьАнтивирусная правДА! рекомендует
- Советуем не хранить важные данные в Интернете. Поверьте, на множестве ресурсов они видны всем желающим и без всяких хакеров.
- Если выкладываете в Интернет что-то ценное, защитите паролем (отличным от 1234).
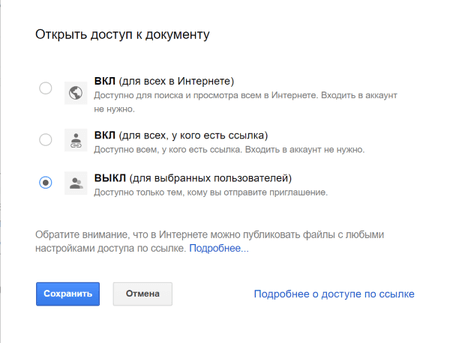
- В Google Docs предусмотрено три основных режима доступа к документу: «для всех в Интернете»; «для всех, у кого есть ссылка» (именно документы с этим видом доступа проиндексировал «Яндекс») и «для выбранных пользователей» – доступ к документу получат только те, кого вы пригласите. Приглашенному пользователю придется войти в свою учетную запись, чтобы получить возможность просматривать и/или редактировать документ, а все его действия будут фиксироваться в истории редактирования документа. Именно этот режим мы и рекомендуем использовать.

|
Оцените выпуск Чтобы проголосовать зайдите в аккаунт на сайте или создайте его, если аккаунта еще нет.
|
Сделайте репост
|
![[ВКонтакте]](http://st.drweb.com/static/new-www/social/no_radius/vkontakte.png)
![[Twitter]](http://st.drweb.com/static/new-www/social/no_radius/twitter.png)
{kind=link}
{kind=link}
{kind=link}
Необходимо войти на страницу выпуска через аккаунт на сайте «Доктор Веб» (или создать аккаунт). Аккаунт должен быть связан с вашим аккаунтом в социальной сети. Видео о связывании аккаунта.
Нам важно ваше мнение
Чтобы оставить комментарий, нужно зайти через свой аккаунт на сайте «Доктор Веб». Если аккаунта еще нет, его можно создать.
Комментарии пользователей
Денисенко Павел Андреевич
21:34:28 2018-08-06
Любитель пляжного футбола
16:53:05 2018-07-18
a13x
02:39:08 2018-07-18
anatol
14:18:43 2018-07-11
Неуёмный Обыватель
11:03:26 2018-07-11
a13x
09:40:29 2018-07-11
Людмила
08:17:25 2018-07-11
всегда и только Бастион был коробкой. а в электронных лицензиях - Dr.Web Security Space + криптограф. Встраивать его в Dr.Web мы не собираемся, насколько я знаю.
Sasha50
05:40:51 2018-07-11
Sasha50
05:38:29 2018-07-11
Неуёмный Обыватель
00:46:27 2018-07-11
Вот ведь действительно, ухватились за жареную новость и делают свои темные дела, играя на любопытстве и жадности.
Неуёмный Обыватель
00:30:48 2018-07-11
Файлы не содержат ничего, кроме изображения и ссылки, вызываемой при клике на изображение. Ссылка ведет на сайт, который по мнению УРоЛога Dr.Web находится в базе вредоносных сайтов Dr.Web!
Вот ведь шельмецы и на этой новости сыграли! У кого нет антивируса или кто отключил кое-каике его компоненты, влетит в неприятную ситуацию.
Lia00
23:43:28 2018-07-10
vla_va
22:46:32 2018-07-10
razgen
22:05:28 2018-07-10
При этом не надо скачивать приложение и устанавливать "Автоматическую загрузку и синхронизацию".
Не надо устанавливать совместный доступ к файлам и папкам. Чтобы другие пользователи могли просматривать, редактировать и скачивать ваши файлы и все остальные навороты.
Да если ещё и поставить на архивы пароль, то шансы потерять данные минимальные, надёжнее чем при хранении на флэшке. Ведь потерять данные можно и на флэшке.
Хотя компании поставщики позиционируют, что "Облако" — это не просто онлайн-хранилище, а скорее рабочая среда.
А если использовать все эти возможные функционалы рабочей среды "облака" которые предлагает поставщик,то риски потерять информацию возрастают.
В...а
21:39:06 2018-07-10
НинаК
21:07:35 2018-07-10
orw_mikle
21:07:17 2018-07-10
Andromeda
20:50:56 2018-07-10
ek
20:08:25 2018-07-10
Альфа
19:58:14 2018-07-10
Сергей
19:57:08 2018-07-10
kva-kva
19:39:33 2018-07-10
mk.insta
19:18:35 2018-07-10
Шалтай Александр Болтай
19:12:37 2018-07-10
Омар Хайям всегда в тему!
Шалтай Александр Болтай
19:10:50 2018-07-10
Так вот она какая - всемирная паутина?
Шалтай Александр Болтай
19:06:57 2018-07-10
aleks_ku
18:53:01 2018-07-10
DrKV
18:47:31 2018-07-10
МЕДВЕДЬ
18:38:19 2018-07-10
Dvakota
18:19:52 2018-07-10
Sasha50
17:30:08 2018-07-10
Татьяна
17:23:06 2018-07-10
На происки судьбы злокозненной не сетуй,
Не утопай в тоске, водой очей согретой!
И дни и ночи пей пурпурное вино,
Пока не вышел ты из круга жизни этой.
Sasha50
17:11:41 2018-07-10
Biggurza
17:06:50 2018-07-10
Все правильно, друзья мои!
Когда вокруг всё проза, проза.
Улыбку вызовут стихи
И мне помогут от …склероза.
User ZZZ
16:43:48 2018-07-10
Татьяна
16:35:11 2018-07-10
Неуёмный Обыватель
16:33:00 2018-07-10
"Но если зайти просто в раздел "Коробки", то там Бастион находится. https://products.drweb.ru/box/bastion/?page=80"
Просто мне показалось странным, что его нет в списке продуктов для дома, вот и закралась шальная мысль- уж не готовится ли встраивание криптографа в функционал основного продукта :)
Sasha50
16:15:17 2018-07-10
Sasha50
16:12:59 2018-07-10
La folle
16:10:25 2018-07-10
Sasha50
16:09:14 2018-07-10
Ruslan
15:52:47 2018-07-10
achemolganskiy
15:48:35 2018-07-10
Мюллер- знают двое, знает и свинья. Инет не двое-?????. Инфу храни по старинке.
Людмила
15:48:03 2018-07-10
насчет подвижек. разработчик не мы. от нас в его разработке ничего не зависит.
Людмила
15:46:48 2018-07-10
Есть Бастион: https://products.drweb.ru/box/compare/
обидно, что вы его не увидели. Он в разделе коробки...
Неуёмный Обыватель
15:17:15 2018-07-10
Стих слагать вы уж горазды,
Не угнаться нам за вами.
Нет замков, но есть пароли:
qwerty, три-четыре-пять.
На утечки всем плевать,
Будем в облако всё гнать.
Владимир
14:51:55 2018-07-10
Геральт
14:30:02 2018-07-10
Toma
14:27:19 2018-07-10
Biggurza
14:06:40 2018-07-10
Призрак запертых замков?
@I23,: «Но не испортят нам обедни
Злые происки врагов».
Умоляю, посмотрите
Что там в поиске у вас?
Свой пароль пересмотрите –
Очень радует он вас?
Dr.Web не даст обжечься,
Душит-давит вредонос.
Но, выгодна кому утечка
Наших данных? Вот вопрос…